1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
| import requests
import time
import json
from pymongo import MongoClient
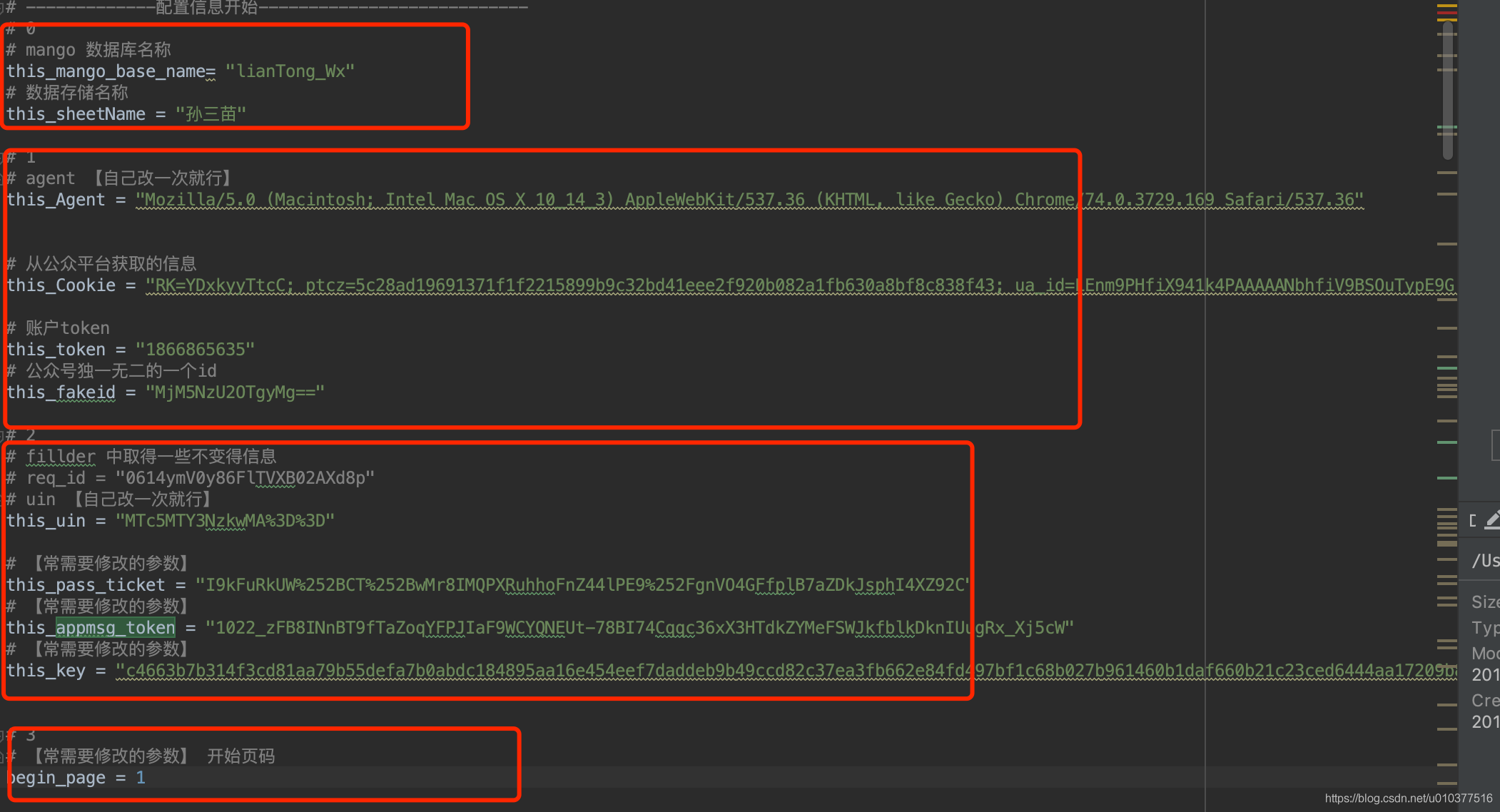
this_mango_base_name= "lianTong_Wx"
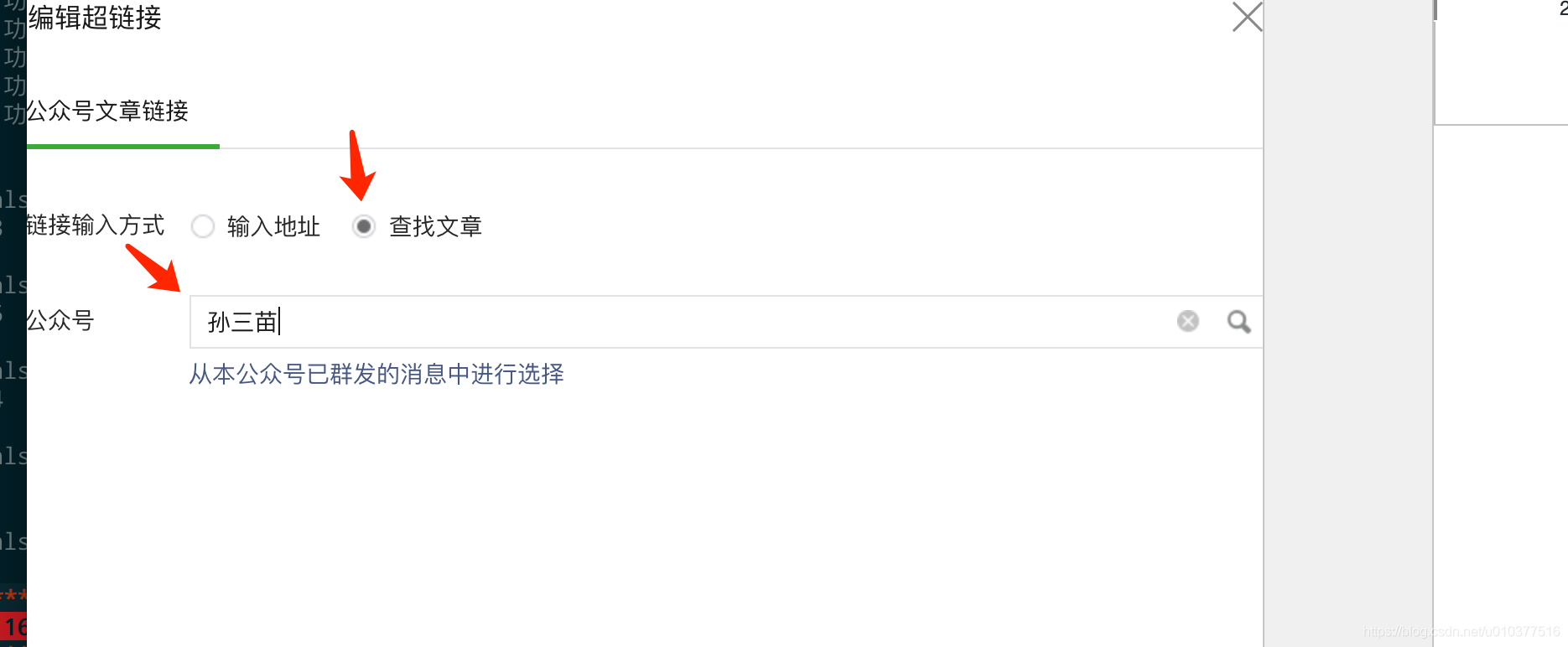
this_sheetName = "孙三苗"
this_Agent = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36"
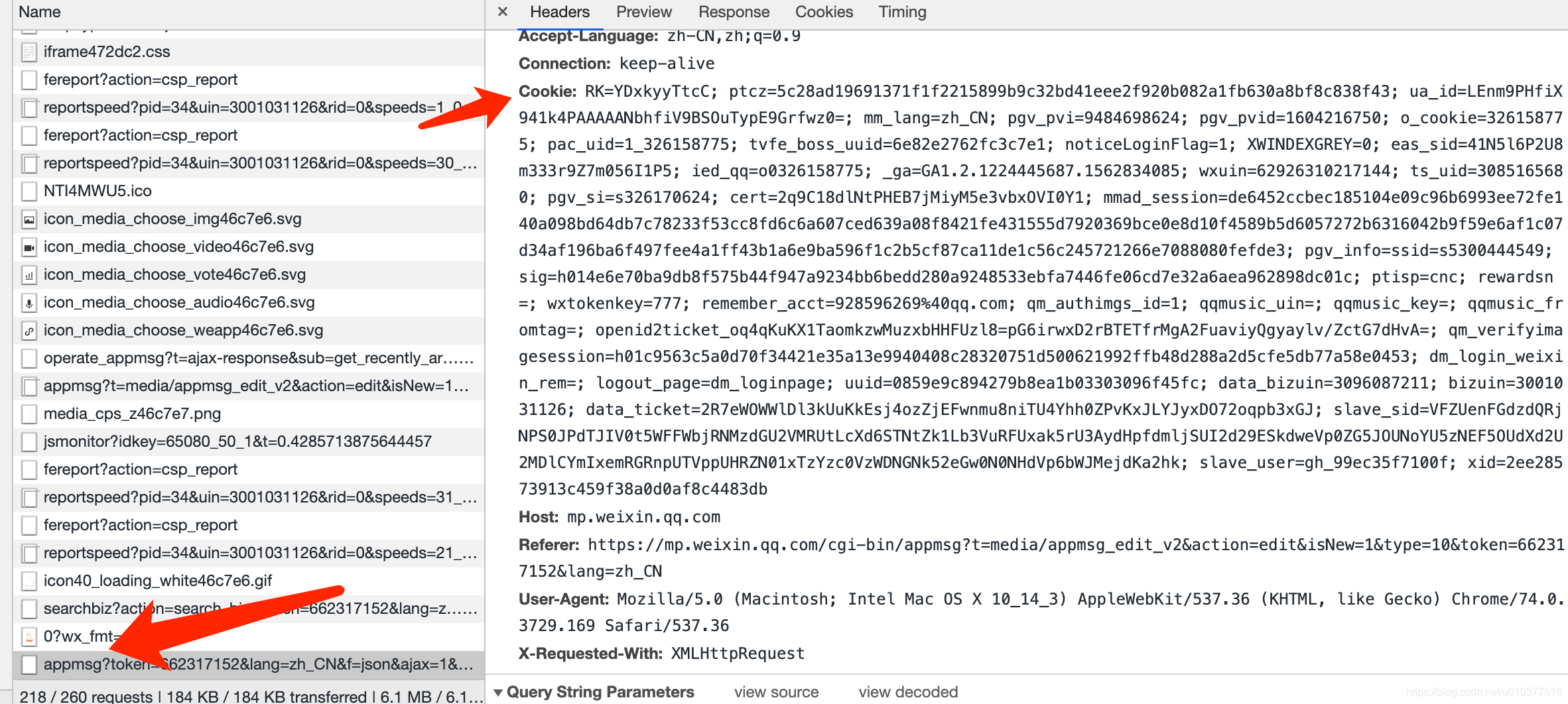
this_Cookie = "RK=YDxkyyTtcC; ptcz=5c28ad19691371f1f2215899b9c32bd41eee2f920b082a1fb630a8bf8c838f43; ua_id=LEnm9PHfiX941k4PAAAAANbhfiV9BSOuTypE9Grfwz0=; mm_lang=zh_CN; pgv_pvi=9484698624; pgv_pvid=1604216750; o_cookie=326158775; pac_uid=1_326158775; tvfe_boss_uuid=6e82e2762fc3c7e1; noticeLoginFlag=1; XWINDEXGREY=0; eas_sid=41N5l6P2U8m333r9Z7m056I1P5; ied_qq=o0326158775; _ga=GA1.2.1224445687.1562834085; wxuin=62926310217144; ts_uid=3085165680; pgv_si=s326170624; cert=2q9C18dlNtPHEB7jMiyM5e3vbxOVI0Y1; mmad_session=de6452ccbec185104e09c96b6993ee72fe140a098bd64db7c78233f53cc8fd6c6a607ced639a08f8421fe431555d7920369bce0e8d10f4589b5d6057272b6316042b9f59e6af1c07d34af196ba6f497fee4a1ff43b1a6e9ba596f1c2b5cf87ca11de1c56c245721266e7088080fefde3; pgv_info=ssid=s5300444549; sig=h014e6e70ba9db8f575b44f947a9234bb6bedd280a9248533ebfa7446fe06cd7e32a6aea962898dc01c; ptisp=cnc; rewardsn=; wxtokenkey=777; remember_acct=928596269%40qq.com; qm_authimgs_id=1; qqmusic_uin=; qqmusic_key=; qqmusic_fromtag=; openid2ticket_oq4qKuKX1TaomkzwMuzxbHHFUzl8=pG6irwxD2rBTETfrMgA2FuaviyQgyaylv/ZctG7dHvA=; qm_verifyimagesession=h01c9563c5a0d70f34421e35a13e9940408c28320751d500621992ffb48d288a2d5cfe5db77a58e0453; uuid=efb1a396d6b9523590e50a287ce2526e; data_bizuin=3096087211; bizuin=3001031126; data_ticket=6B1hXI/GGiMgCSvAlhkIgds5AB3ObpyvSNjUgEgBZJmswjt1VlnnUxPNyFGW9hJC; slave_sid=ZzNTOHJ3UFBTYWJKcXY5eVhoRTlPa2tIazhuSjBJaW85RlRJTVNJZVNBbnRYYVFjTW1ZaTNvWG1GMGJ1eTdSMEtGamIyblo4OHdLMU04eFF6MlB0RWhUQTRKMkRMMHdFRHdvcEhhNV80Y0NYQ1NKa3piTUFJQ3dWbGpGN3FZc1N2Y1dja3Y2eDlhVnhnNEVO; slave_user=gh_99ec35f7100f; xid=b3cf27a3c009e2e32e56d1e75ac944eb"
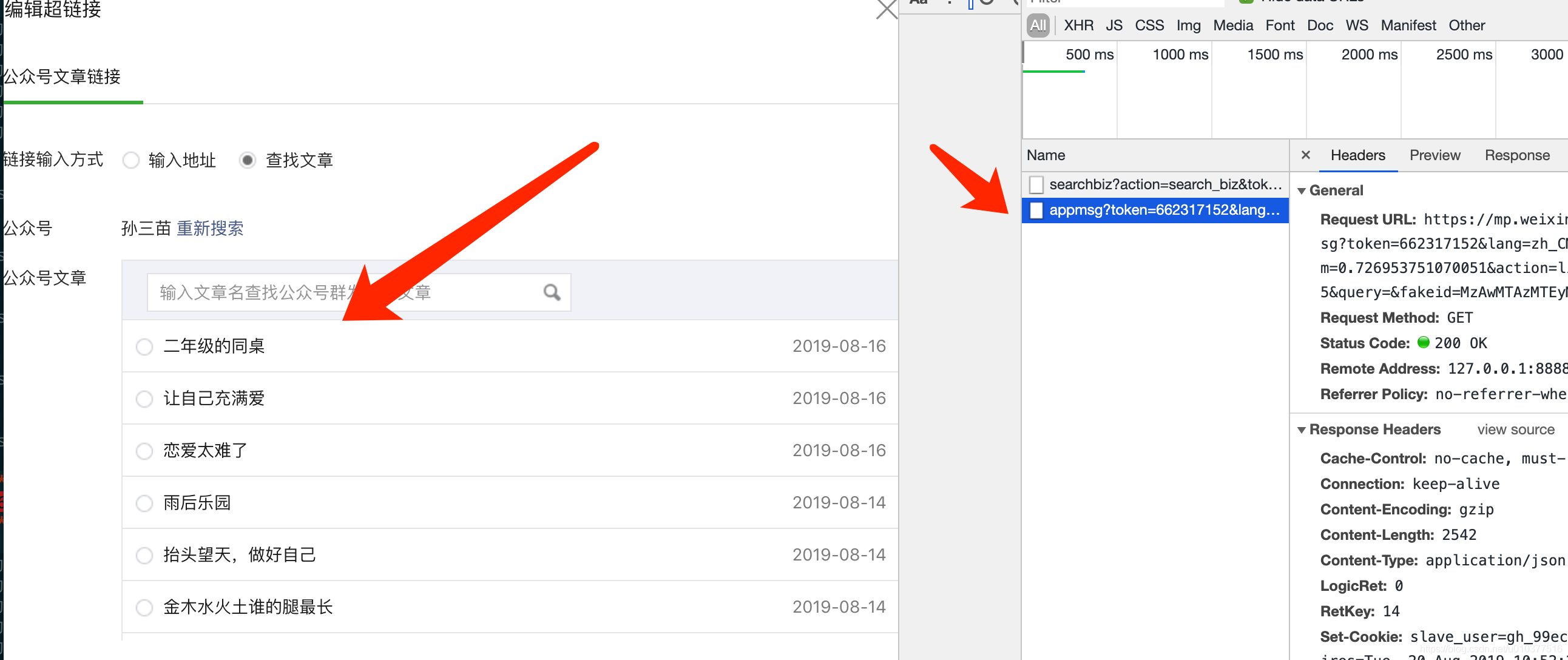
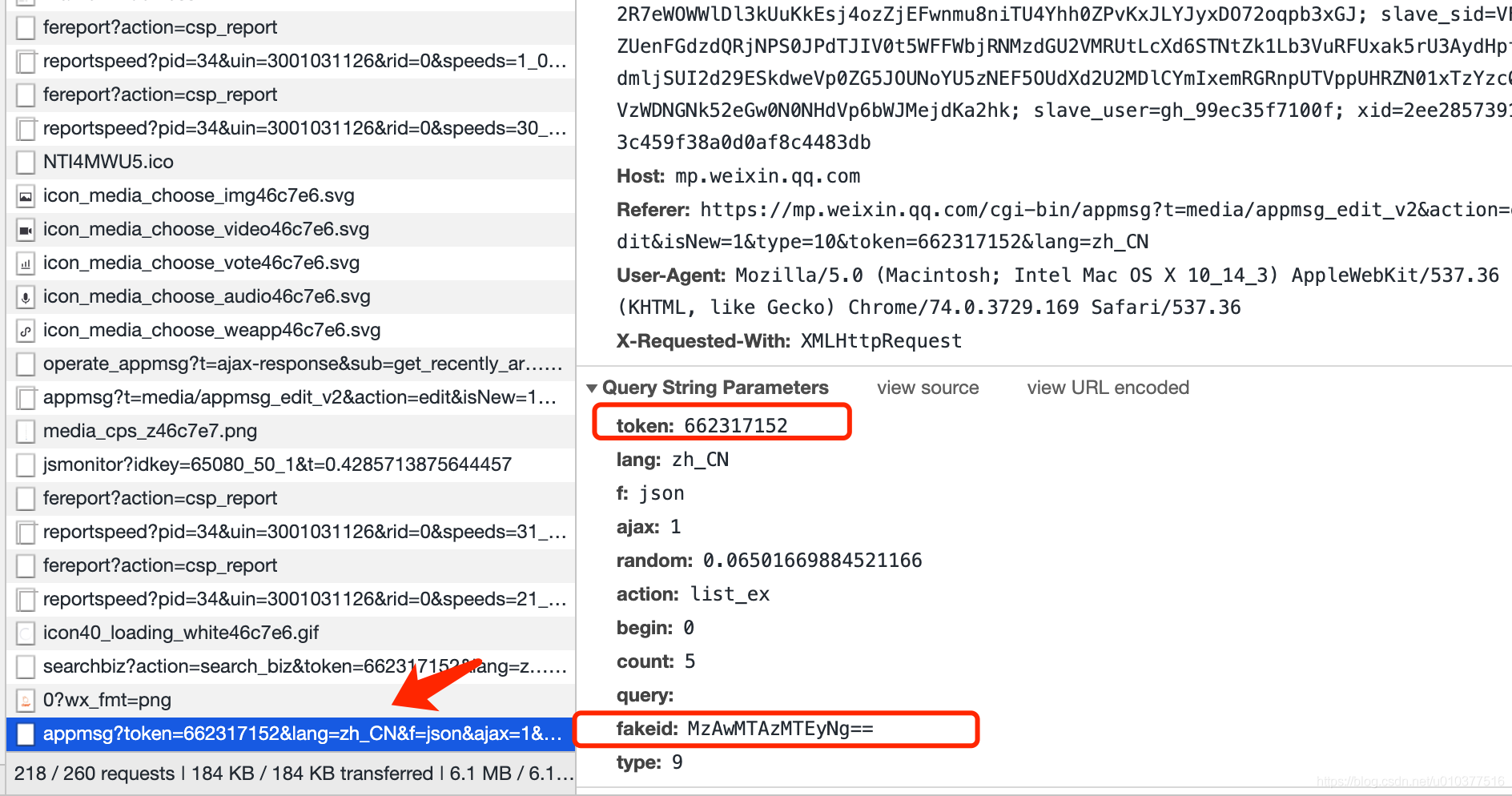
this_token = "1866865635"
this_fakeid = "MjM5NzU2OTgyMg=="
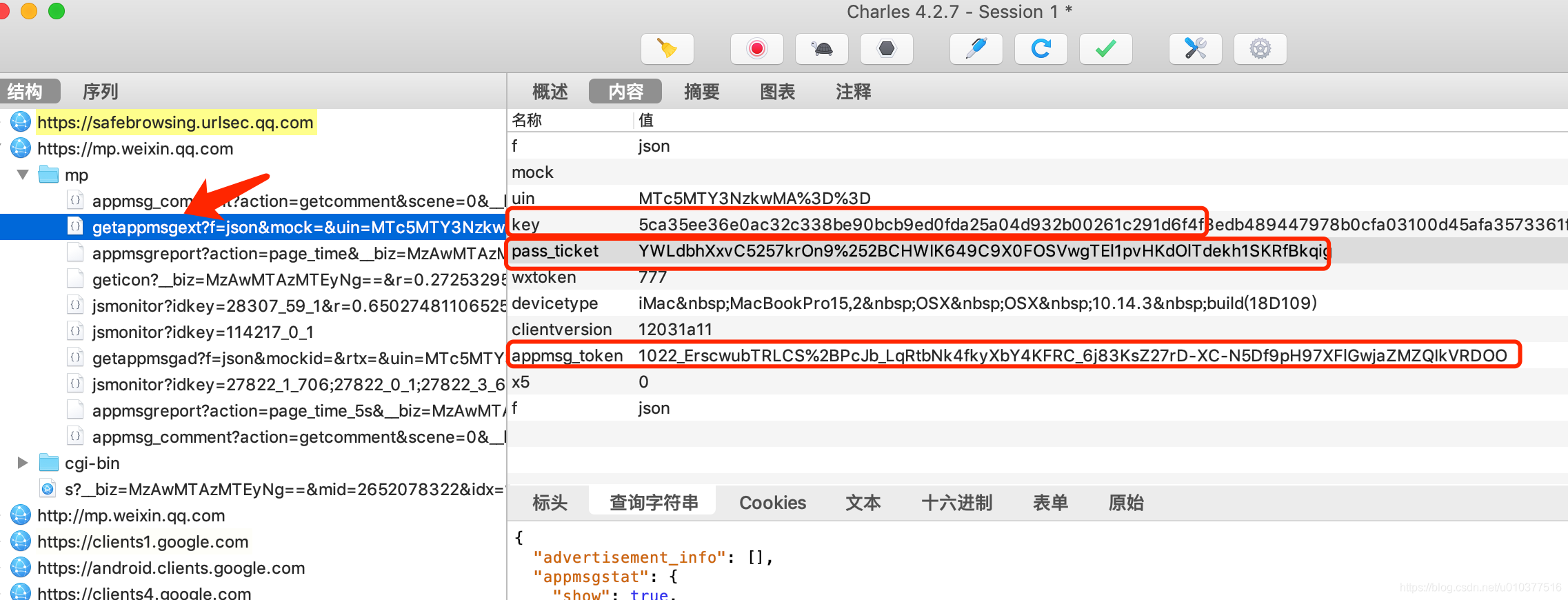
this_uin = "MTc5MTY3NzkwMA%3D%3D"
this_pass_ticket = "I9kFuRkUW%252BCT%252BwMr8IMQPXRuhhoFnZ44lPE9%252FgnVO4GFfplB7aZDkJsphI4XZ92C"
this_appmsg_token = "1022_zFB8INnBT9fTaZoqYFPJIaF9WCYQNEUt-78BI74Cqqc36xX3HTdkZYMeFSWJkfblkDknIUugRx_Xj5cW"
this_key = "c4663b7b314f3cd81aa79b55defa7b0abdc184895aa16e454eef7daddeb9b49ccd82c37ea3fb662e84fd497bf1c68b027b961460b1daf660b21c23ced6444aa17209b89f80dcf714d8466f5ec2f1880a"
begin_page = 1
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
Cookie = this_Cookie
headers = {
"Cookie": Cookie,
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.0.3 Safari/605.1.15",
}
"""
需要提交的data
以下个别字段是否一定需要还未验证。
注意修改yourtoken,number
number表示从第number页开始爬取,为5的倍数,从0开始。如0、5、10……
token可以使用Chrome自带的工具进行获取
fakeid是公众号独一无二的一个id,等同于后面的__biz
"""
token = this_token
fakeid = this_fakeid
type = '9'
data1 = {
"token": token,
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"begin": "365",
"count": "5",
"query": "",
"fakeid": fakeid,
"type": type,
}
def getDate(times):
timearr = time.localtime(times)
date = time.strftime("%Y-%m-%d %H:%M:%S", timearr)
return date
def getMoreInfo(link):
mid = link.split("&")[1].split("=")[1]
idx = link.split("&")[2].split("=")[1]
sn = link.split("&")[3].split("=")[1]
_biz = link.split("&")[0].split("_biz=")[1]
uin = this_uin
pass_ticket = this_pass_ticket
appmsg_token = this_appmsg_token
key = this_key
url = "http://mp.weixin.qq.com/mp/getappmsgext"
phoneCookie = "wxtokenkey=777; rewardsn=; wxuin=2529518319; devicetype=Windows10; version=62060619; lang=zh_CN; pass_ticket=4KzFV+kaUHM+atRt91i/shNERUQyQ0EOwFbc9/Oe4gv6RiV6/J293IIDnggg1QzC; wap_sid2=CO/FlbYJElxJc2NLcUFINkI4Y1hmbllPWWszdXRjMVl6Z3hrd2FKcTFFOERyWkJZUjVFd3cyS3VmZHBkWGRZVG50d0F3aFZ4NEFEVktZeDEwVHQyN1NrNG80NFZRdWNEQUFBfjC5uYLkBTgNQAE="
headers = {
"Cookie": phoneCookie,
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 MicroMessenger/6.5.2.501 NetType/WIFI WindowsWechat QBCore/3.43.901.400 QQBrowser/9.0.2524.400"
}
data = {
"is_only_read": "1",
"is_temp_url": "0",
"appmsg_type": "9",
'reward_uin_count':'0'
}
"""
添加请求参数
__biz对应公众号的信息,唯一
mid、sn、idx分别对应每篇文章的url的信息,需要从url中进行提取
key、appmsg_token从fiddler上复制即可
pass_ticket对应的文章的信息,也可以直接从fiddler复制
"""
params = {
"__biz": _biz,
"mid": mid,
"sn": sn,
"idx": idx,
"key": key,
"pass_ticket": pass_ticket,
"appmsg_token": appmsg_token,
"uin": uin,
"wxtoken": "777",
}
content = requests.post(url, headers=headers, data=data, params=params).json()
try:
readNum = content["appmsgstat"]["read_num"]
print(readNum)
except:
readNum=0
try:
likeNum = content["appmsgstat"]["like_num"]
print(likeNum)
except:
likeNum=0
try:
comment_count = content["comment_count"]
print("true:" + str(comment_count))
except:
comment_count = -1
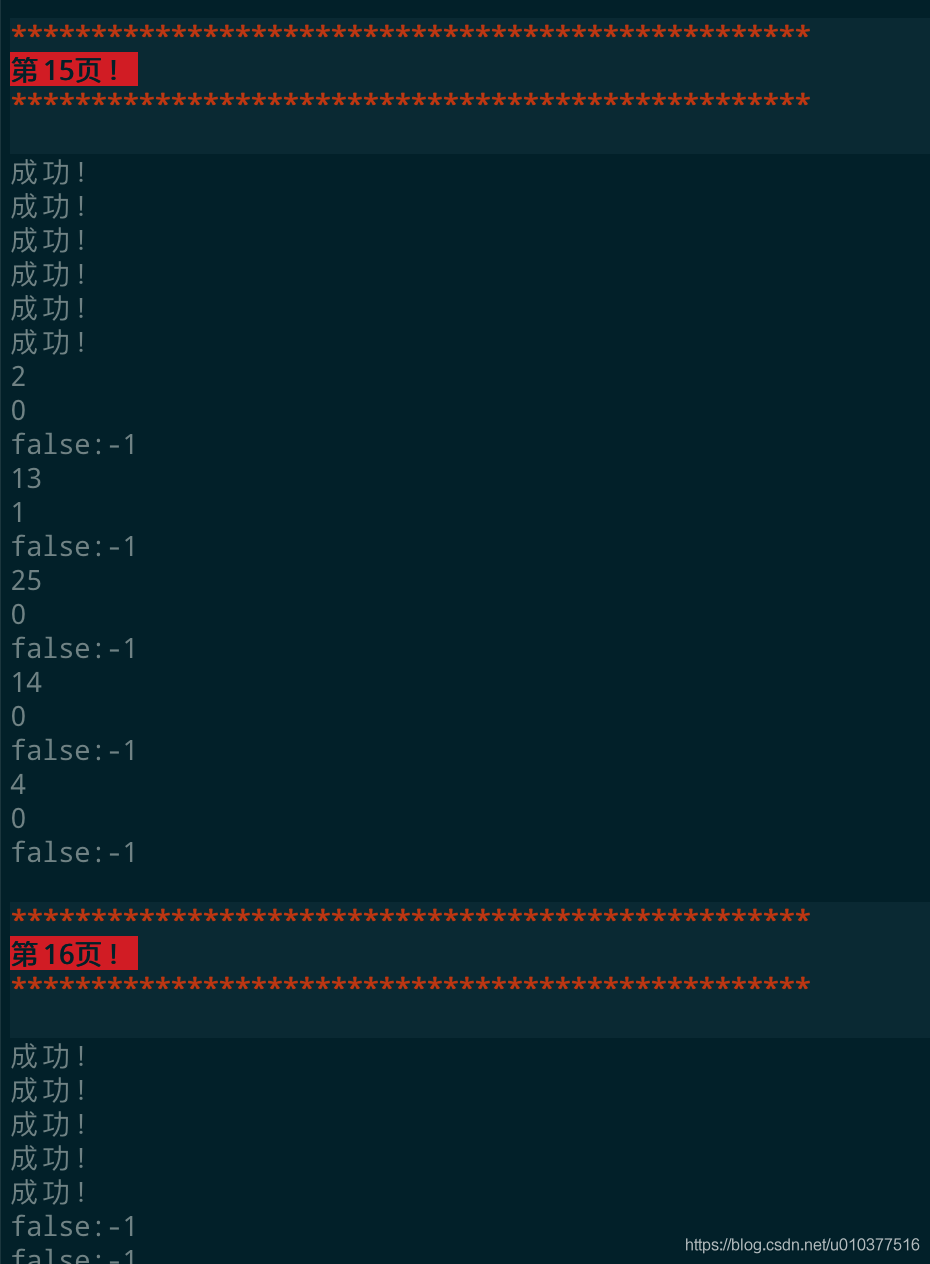
print("false:" + str(comment_count))
time.sleep(3)
return readNum, likeNum,comment_count
def getAllInfo(url, begin):
messageAllInfo = []
data1["begin"] = begin
content_json = requests.get(url, headers=headers, params=data1, verify=False).json()
time.sleep(3)
if "app_msg_list" in content_json:
for item in content_json["app_msg_list"]:
url = item['link']
readNum, likeNum ,comment_count= getMoreInfo(url)
info = {
"title": item['title'],
"readNum": readNum,
"likeNum": likeNum,
'comment_count':comment_count,
"digest": item['digest'],
"date": getDate(item['update_time']),
"url": item['link']
}
messageAllInfo.append(info)
return messageAllInfo
def putIntoMogo(urlList):
host = "127.0.0.1"
port = 27017
client = MongoClient(host, port)
lianTong_Wx = client[this_mango_base_name]
wx_message_sheet = lianTong_Wx[this_sheetName]
if urlList is not None:
for message in urlList:
wx_message_sheet.insert_one(message)
print("成功!")
def main():
for i in range(begin_page, 365):
begin = i * 5
messageAllInfo = getAllInfo(url, str(begin))
print('\033[1;31;40m')
print('*' * 50)
print("\033[7;31m第%s页!\033[1;31;40m\033[0m\033[1;31;40m" % i)
print('*' * 50)
print('\033[0m')
putIntoMogo(messageAllInfo)
if __name__ == '__main__':
main()
|